
求人検索エンジンで使用するラベル付与の話
はじめに
スタンバイでは求人検索エンジンにラベル情報での検索を可能にしています。
ラベルとは求人情報や検索キーワードの特徴的な情報に対するTag付けと考えていただければイメージしやすいかと。
本記事ではRuleによるラベル付けをテーマとしています。
ラベルの使い所
例として「住吉」という駅の求人を検索する場合を挙げます。住吉という駅は全国に下記の数存在します。
- 東京都 住吉駅
- 大阪府 住吉駅
- 熊本県 住吉駅
- 長崎県 住吉駅
- 兵庫県 住吉駅(JR西日本)
- 兵庫県 住吉駅(阪神電鉄)
「住吉駅」という単語のみで検索する際は上記全ての駅の求人データが対象となりますが、「半蔵門線 住吉駅」の場合は「半蔵門線」は東京にある路線なので、1の「東京都 住吉駅」のみが対象となって欲しいところです。しかし、「東京都 住吉」の求人データに「半蔵門線」の記述がない場合には絞り込むことができません。そこで駅名周辺情報から同一駅名でも別物と扱える仕組みとしてラベルを導入しています。
複数の同一駅名から絞り込む情報として、都道府県、路線名を使用しています。東京都、大阪府の住吉駅であれば以下の絞り込み情報との組み合わせが挙げられます。

このように同じ「住吉駅」であっても周辺情報を活用し、ラベル付与すれば区別できます。
区別できればこのラベル情報を用いて、より意図に近いものを検索することが可能になります。
ラベル付けを行うにはMLかRuleか
ラベル付けを行うにあたり考えられる手法は大きく分けてRuleベースと機械学習の2つが挙げられます。 2つの手法のメリット・デメリットをまとめると以下ようになります。
| メリット | デメリット | |
|---|---|---|
| Ruleベース | 高速 学習データ作成不要 |
Ruleで表現できないものは対応不可 |
| 機械学習 | Ruleで表現できないものに対応可能 | 学習データ作成負荷が高い |
どちらを採用するかというとHybridな形で行うのがBetterかと考えます。
単語の有無で決定できるようなラベル付けまで機械学習を使う必要はありません。
しかし、Ruleで表現できないものもあるので機械学習を使用しないという選択肢もありません。
まずはRuleベースでラベル付けを実施、その後まかない切れない部分を機械学習で補う形としています。
Ruleベースの機能定義
Ruleベースには下記の5つの機能を実装しました。
- 単語の有無Rule機能
指定単語の有無によりラベルを付与、削除する - 単語の組み合わせRule機能
2つ以上の単語の組み合わせの有無によりラベルを付与、削除する - ラベルと単語の組み合わせRule機能
付与したラベルと単語の組み合わせによりラベルを付与、削除する - Rule適用順序機能
Ruleの適用に順序を設け、ラベルを付与する順序を制御する
例:
順序1. 東京に対して駅ラベルを付与
順序2. 東京都の場合には駅ラベルを削除 - ラベル付与先の指定機能
ラベルを付与する形態素を制御する
例:
都営新宿線 住吉駅の住吉駅にのみラベルを付与する場合に使用 都営新宿線, 住吉駅ともにRule条件だが、駅ラベルを付与する場合には路線名には付与したくない場合がある
構成
開発言語 : Rust
構成Module :
- 形態素解析
Rust製のLinderaを使用しています。社内にLinderaのMaintainerがいることもあり、採用しました。 - DoubleArray
- RuleEngine
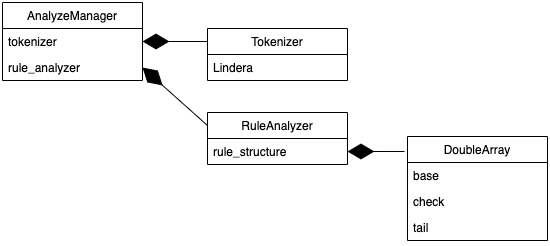
DoubleArray
Ruleを検索するのにDoubleArrayを使用しています。DoubleArrayの詳しい説明はここでは割愛します。
DoubleArrayの概要はこちらのページが簡潔にまとまっていて理解しやすいです。
取り立てて特別なことはしていませんが、DoubleArrayの検索状態を維持しながら検索を行えるようにしています。
例としては下記になります。
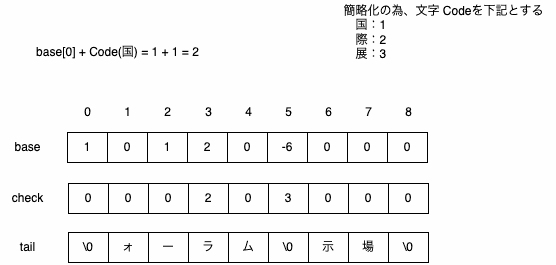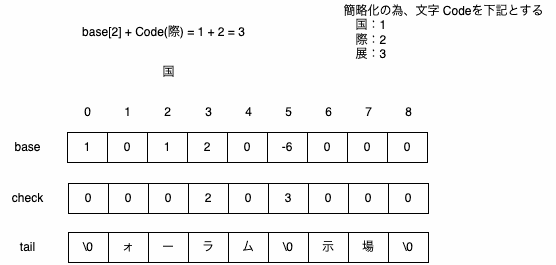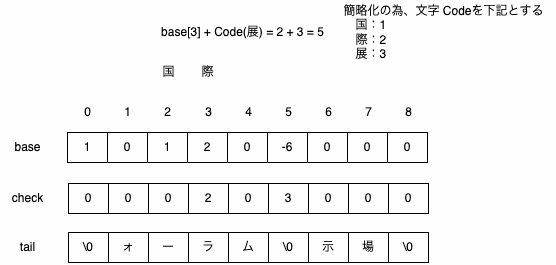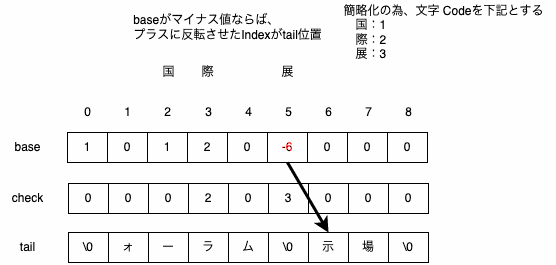
DoubleArrayに追加する情報
・国際フォーラム
・国際展示場
検索する文字列
・国際展示場駅
検索時の形態素解析された[国際 展示 場 駅]で、下記のように文字列を作成して検索するのは非効率
・国際
・国際展示
・国際展示場
・国際展示場駅
DoubleArrayのbase、check、tailの状態を保持しておけば前回の検索結果の続きから検索することが可能
RuleEngine
上記の「住吉駅」のRuleをjsonで表現すると下記のようになります。
1001 : 東京都の住吉駅
1002 : 大阪府の住吉駅
{"order":1, "add_label":[[1, [1001, 1002]]], "word_rule":[{"word":"住吉駅"}]}
{"order":2, "del_label":[[1, [1002]]], "word_rule":[{"word":"東京都"}, {"word":"住吉駅"}]}
{"order":2, "del_label":[[1, [1002]]], "word_rule":[{"word":"新宿線"}, {"word":"住吉駅"}]}
{"order":2, "del_label":[[1, [1002]]], "word_rule":[{"word":"半蔵門線"}, {"word":"住吉駅"}]}
{"order":2, "del_label":[[1, [1001]]], "word_rule":[{"word":"大阪府"}, {"word":"住吉駅"}]}
{"order":2, "del_label":[[1, [1001]]], "word_rule":[{"word":"上町線"}, {"word":"住吉駅"}]}
{"order":2, "del_label":[[1, [1001]]], "word_rule":[{"word":"阪堺線"}, {"word":"住吉駅"}]}
jsonの各項目は以下の内容を表しています。
order : Ruleの適用順を表す。小さい値のRuleから順にRuleを適用する。
add_label : ラベルを付与するword_rule上の形態素Indexとそのラベル名。
del_label : ラベルを削除するword_rule上の形態素Indexとそのラベル名。
word_rule : 構成要素の「word」と「labels」が解析文章と一致すれば、「add_label」, 「del_label」を適用する。
word : 形態素表記と同一の文字列が解析文章に存在すれば一致とする。
複数ある場合は、記述されいてる順序もRule条件となる。
上記の "word_rule":[{"word":"東京都"}, {"word":"住吉駅"}] では、以下のようになる。
解析文章:「東京都の住吉駅」 Rule一致
解析文章:「住吉駅 東京都」 Rule不一致
labels : 形態素に付与されたラベルが解析文章に存在すれば一致とする。
配列となっておりラベルが複数記述されている場合はAND条件として処理する。
上記のRuleに対して「半蔵門線の住吉駅」を解析するとRule適用は以下の流れで行われます。
order:1のRuleが適用され下記の状態となる
半蔵門線 [] の [] 住吉 [1001, 1002] 駅 [1001, 1002]order:2のRuleが適用され下記の結果となる
半蔵門線 [] の [] 住吉 [1001] 駅 [1001]
Rule検索の全体の流れとしては下記のイメージとなります。

まとめ
Ruleベースを導入することで単純なものならば機械学習を導入しなくとも事足りることを紹介しました。
機械学習は手法の一つであって目的ではないので、最適な手法を採用することが重要と考えます。
スタンバイのプロダクトや組織について詳しく知りたい方は、気軽にご相談ください。 www.wantedly.com