 初めまして、スタンバイのソフトウェアエンジニアを務めておりますの一般エンジニアです。
初めまして、スタンバイのソフトウェアエンジニアを務めておりますの一般エンジニアです。
ChatGPTの流行により大規模言語モデル (LLM) が注目を集める中、生成AIの開発はさらに活発化しています。その中でも注目されているのが、RAG (Retrieval Augmented Generation) です。これは、外部ソースから関連情報を検索し、生成されたコンテンツに組み込むことで、より情報量が多く正確なテキストを生成する手法です。
本記事は、今年初めに社内向け作成したLLMとVespa活用プロトタイプの内容を再構成したものです。当時の Vespa 最新機能 (2024.03 時点) を用いてLLMの可能性を検証するデモでしたが、生成AIの開発は日々急速に進んでいるため、記事内容は最新の情報を完全に反映していない可能性があります。ご了承ください。
背景
Vespa は、検索やレコメンドなど、ハイパフォーマンスなサービングユースケース向けに設計された、オープンソースのサービングエンジンです。テキスト検索、ベクター検索、マルチフェーズ検索やランキングなどを含むハイブリッド検索など、最先端の機能を備えています。Vespaの詳細は、公式サイト をご覧ください。
スタンバイでは、検索エンジン基盤としてVespaを採用しています。Vespa移行の詳細については、下記の同僚の記事をご覧ください。
プロトタイプアイデア
スタンバイは、コアとなる求人検索エンジン だけではなく、求職関連メディアサイト「スタンバイPlus」も運営しています。「スタンバイPlus」では専門家によるレビュー・編集済みの求職者向けの高品質なアドバイス、各種職種紹介など、様々なコンテンツを提供しています。
生成AIとサイトコンテンツを組み合わせれば、完全にセルフサービスのAI求職アドバイザーへと変貌し、求職者の疑問や不安に役立つ回答を提供できる可能性があります。
プロトタイプ
「教えて!スタンバイ太郎先生」 という名前のプロトタイプを開発しました。
このプロトタイプは以下のような機能を提供します:
- LLM 生成による質問に対する RAG レスポンス
- Vespaによる多言語セマンティック検索
- LLMによる求職関連クエリの提案
- 質問に関連したスタンバイの求人推薦
プロトタイプの開発に使用したスタックは以下の通りです:
- 検索エンジン: Vespa
- LLMフレームワーク: LangChain
- 基礎モデル: Anthropic Claude 3 Haiku via AWS Bedrock
- Web App: Mercury
プロトタイプの全体的なフローは下記の図のようになっています:
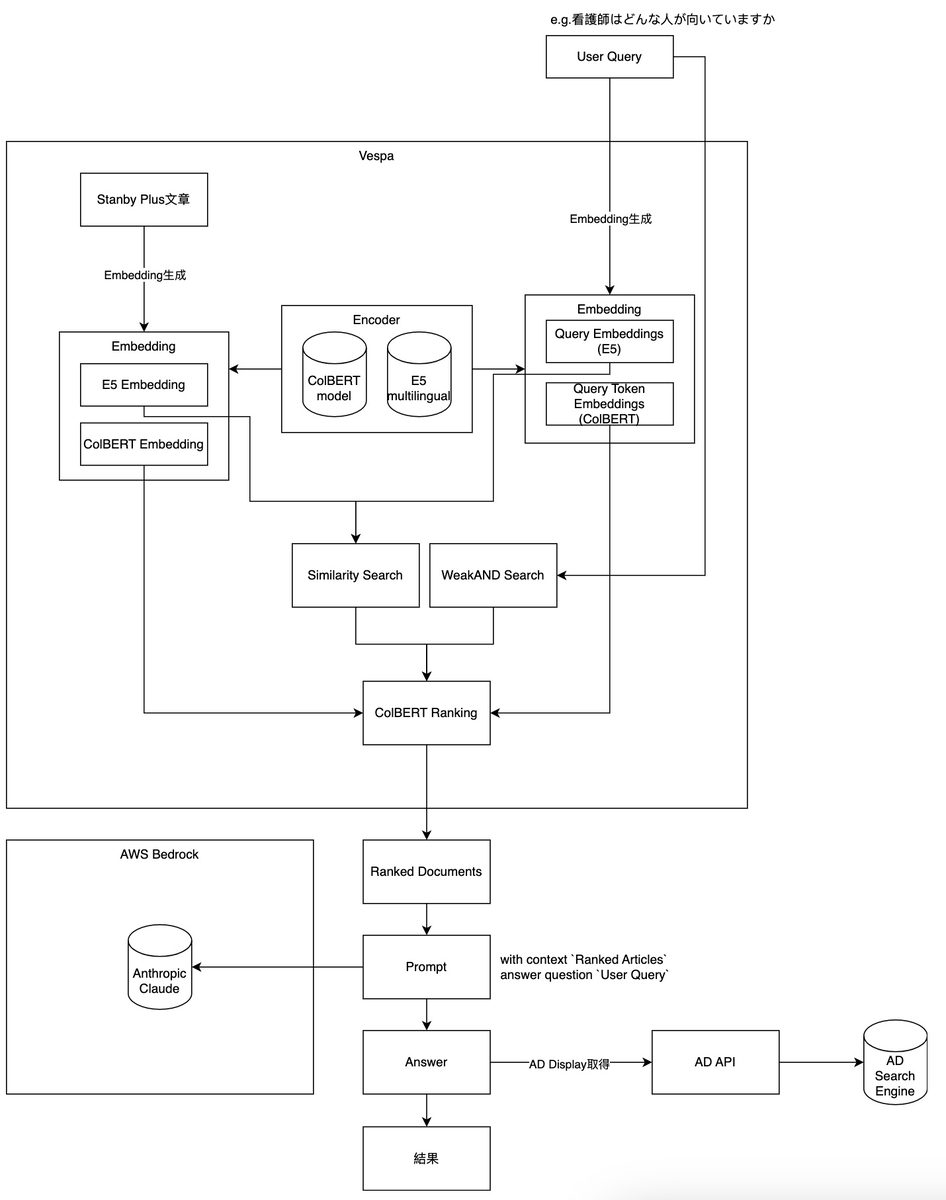
以降のセクションでは、主要部分のデザインの詳細について説明します。
ドキュメント処理
スキーマ
まず、検索エンジンのスキーマを定義します。 今回はプロトタイプなので、検索用の最低限のフィールドのみ定義します。
schema article {
document article {
field title type string {
indexing: summary | index
index: enable-bm25
}
field body type string {
indexing: summary | index
index: enable-bm25
summary : dynamic
}
field path type string {
indexing: summary | index
}
}
field embedding type tensor<float>(x[768]) {
indexing {
"passage: " . (input title || "") . " " . (input body || "") | embed e5 | attribute | index
}
attribute {
distance-metric: angular
}
index: hnsw
}
field colbert_embs type tensor<int8>(token{}, x[16]) {
indexing {
(input title || "") . " " . (input body || "") | embed colbert | attribute
}
}
fieldset default {
fields: title,body
}
}
フィールド
スタンバイPlusの記事は、HTML形式からマークダウン形式に変換され、bodyフィールドに格納されます。
Embedder
新しいバージョンのVespaでは、Vespaクラスターのドキュメントプロセッサ内で直接実行されるEmbedderコンポーネントが導入されました。ドキュメントがVespaに投入されると、このプロセスで自動的にEmbeddingが生成されます。Vespaクラスター内で直接実行されるため、別のベクトル化APIを管理してEmbeddingを作成するための手間とコストが少なくて済みます。
このプロトタイプでは、ドキュメント投入時に2種類のEmbeddingを作成するための2つのEmbedderを定義しました。 1つは検索用のE5 Embedding、もう1つはColBERT Embeddingです。
Embedderは、Vespaクラスターのservices.xmlアプリケーションパッケージファイルに数行追加するだけで定義できます。
<component id="e5" type="hugging-face-embedder"> <transformer-model url="/multilingual-e5-base/model.onnx"/> <tokenizer-model url="/multilingual-e5-base/tokenizer.json"/> </component> <component id="colbert" type="colbert-embedder"> <transformer-model url="/colbert/model.onnx"/> <tokenizer-model url="/colbert/tokenizer.json"/> </component>
URLは説明のためのものであり、実際に使用するURLとは異なります。
Vespa Embedderコンポーネントの詳細については、Vespa のエンベッディングドキュメント を参照してください。
ハイブリッド検索
このプロトタイプでは、従来通りの二段階ランキングを採用しました。
マッチング
マッチングでは、Vespaでネイティブにサポートされている近傍ベースセマンティック検索(Nearest Neighbour Search)とレキシカル検索(Lexical Search)を組み合わせ利用します。(ハイブリッド検索として知られる)
近傍検索のほうがレキシカル検索より優れているのかという議論がよくありますが、レキシカル検索は時代遅れで退役すべきという意見もあります。実際には、レキシカル検索と近傍検索にはそれぞれ長所と短所があり、両方の検索結果を組み合わせることで、両方のメリットを享受できます。
Vespaの得意な点としては、1つの検索リクエストで同時に両方検索できるため、効率的で手間が少なくて済むことです。
Vespaのランクプロファイル関数内で、ファーストフェーズで直接同時検索できるように定義すると、ハイブリッド検索を簡単できます。
first-phase {
expression: nativeRank + closeness(field, embedding)
}
nativeRankスコアはレキシカル検索からのテキストマッチングスコアであり、closenessはクエリとドキュメントのEmbedding間の近さを表します。
各検索からのスコアに重みを付けることもできますが、このプロトタイプでは最適化を行う時間がなかったため、単純に2つのスコアを加算しています。
このプロトタイプでは、デモ目的ですべてが同じマシン上で実行されているため、Embeddingモデルをファインチューニングする時間とリソースがありません。そのため、パフォーマンスと簡便性を考慮して、intfloat/multilingual-e5-baseテキストEmbeddingモデルを使用しています。
プロトタイプで使用したVespa検索エンジンの実際のリクエストは次のようになります。
{ "yql": "select title, body, path from article where (({targetHits:10}nearestNeighbor(embedding,q)) OR weakAnd(userQuery()))", "ranking": { "profile": "colbert" }, "model": { "locale": "ja" }, "hits":"5", "query":"在宅ワークは何の仕事ですか?", "input.query(q)": "embed(e5, \"query: 在宅ワークは何の仕事ですか?\")", "input.query(q_t)": "embed(colbert, \"在宅ワークは何の仕事ですか?\")" }
このプロトタイプでは、Vespa Embedderコンポーネントを使用して、リクエスト時にユーザークエリをEmbeddingに変換し、近傍検索に使用しています。
リランク
リランクステージでは、プロトタイプの目的の1つとして、最新のVespa機能を実証することだったので、ここでColBERTを使用することにしました。
ColBERT (Contextualized Late Interaction over BERT) は、効率的で効果的なドキュメント検索のために設計されたニューラルランキングモデルです。クエリとドキュメントの両方を BERT を使用して密なベクトルにエンコードします。個々のトークンEmbedding間の類似度スコアを計算することで、シーケンス全体ではなく、レイトインタラクションを実行します。
レイトインタラクション(Late Interaction)は、検索クエリとドキュメントを個別に処理し、プロセスの最終段階まで相互作用を遅らせることで、効率的で正確な検索を実現します。検索クエリとドキュメントの表現は、それぞれ独立してエンコードされ、その後相互作用が行われるため、レイトインタラクションと呼ばれています。
これにより、効率性を維持しながら、細かいマッチングが可能になります。ColBERTは、リランキングステージで使用できます。ファーストフェーズで検索された候補ドキュメントをより深い意味的な理解に基づいてランキングの精度を向上させることができます。
残念ながら、Vespa自体はColBERTで使用される類似度スコアを計算するためのMaxSim関数を提供していませんが、Vespaが提供する算術演算子を使用してカスタム関数を作成できます。
以下は、リランクフェーズのランクプロファイルのスニペットです
function maxsim() {
expression {
sum(
reduce(
sum(
query(q_t) * unpack_bits(attribute(colbert_embs)), x
),
max, colbert_embs
),
q_t
)
}
}
second-phase {
expression: maxsim()
}
リクエスト時に変換されたクエリEmbeddingと、フィーディング時に作成されたドキュメントEmbeddingが、セカンドフェーズで使用され、意味的類似度スコアを計算します。計算されたスコアに基づいて結果がソートされます。
レスポンスの生成
LLM
Vespaから記事検索結果を取得した後、これらの記事がRAGのAG(Augmented Generation)部分で使用されます。
ファウンデーションモデルは、AWS Bedrockを介してAnthropic Claude 3 Haikuを使用しました。Claude 3 Haikuは、Claude 3 ファミリーからコンパクトなサイズで即時応答用に設計されたモデルです。個人的なテストは、Haikuを、SonnetやOpusなどのより大きなモデルを使用して生成された応答と比較して、RAGタスクに対して十分であることがわかりました。AWS Bedrockを選択した理由は、スタンバイは主にAWSインフラを使用しているからです。実際には、日本語をサポートしていれば、他のLLMモデルやプロバイダーと置き換えることができます。
プロンプト
このプロトタイプで使用されたプロンプトは、時間の制約により、プロンプトの最適化が行われていません。
プロンプトは日本語ではなく英語を使用しています。他のLLMプロトタイプや内部使用ツールを開発した経験から、プロンプトは日本語ではなく英語を使用しています。Claude 3モデルは日本語のプロンプトの指示を理解できますが、英語のプロンプトの方が定量的および定性的な分析において、日本語よりも一般的に優れた応答を提供するためです。そのため、ここも主に英語をプロンプトに使用しています。
プロンプト自体は、検索結果を格納する {context} と、ユーザークエリを格納する {query} の 2 つの変数のみを受け取ります。以下は、このプロトタイプで使用された実際のプロンプトです。
You are a helpful, precise, factual Japanese speaking Job Seeking Advice expert who answers questions and user instructions about Job Seeking-related topics. The documents you are presented with are retrieved from a Japanese Job Seeking Advice Blog called Stanby Plus (スタンバイPlus).
Facts about Stanby Plus:
- Stanby Plus is a magazine website operated by Stanby Inc. which operate a Japanese Job Search Engine Services called Stanby (スタンバイ).
- Stanby is a focus on the Japanese market.
<instructions>
- The retrieved documents are markdown formatted text from a Japanese Job Seeking Advice Blog operated by Stanby, a Japanese based Job Search Engine company.
- Answer questions truthfully and factually using only the information presented.
- If you don't know the answer, just say that you don't know, don't make up an answer!
- If you can't answer with reference to the document provided, just say 「大変申し訳ございません。検索されたクエリが適切的に答えができまん。」
- You are correct, factual, precise, and reliable.
- You must reply in Japanese.
- You should reply in less than 500 words.
</instructions>
<articles>
{context}
</articles>
Question: {query}
Helpful factual answer:
プロトタイプは Jupyter Notebook 上で直接実行されるため、LangChain を使用して AWS Bedrock を通じて LLM とやり取りしています。ウェブアプリ自体は、Jupyter Notebook をウェブアプリに変換する Python ライブラリであるMercuryを使用して構築されています。
また、LLMを使用してユーザーの質問から求人検索クエリを作成し、求人推薦を表示する試みも行いました。LLMは、このサブタスクでも良い性能を発揮しました。

デモ
プロトタイプは内部デモ用なので、公開はしていませんが、プロトタイプのスクリーンショットをいくつか紹介します。
 生成された応答のなかで、スタンバイの求人検索サービスを自然に推奨しています 👍
生成された応答のなかで、スタンバイの求人検索サービスを自然に推奨しています 👍
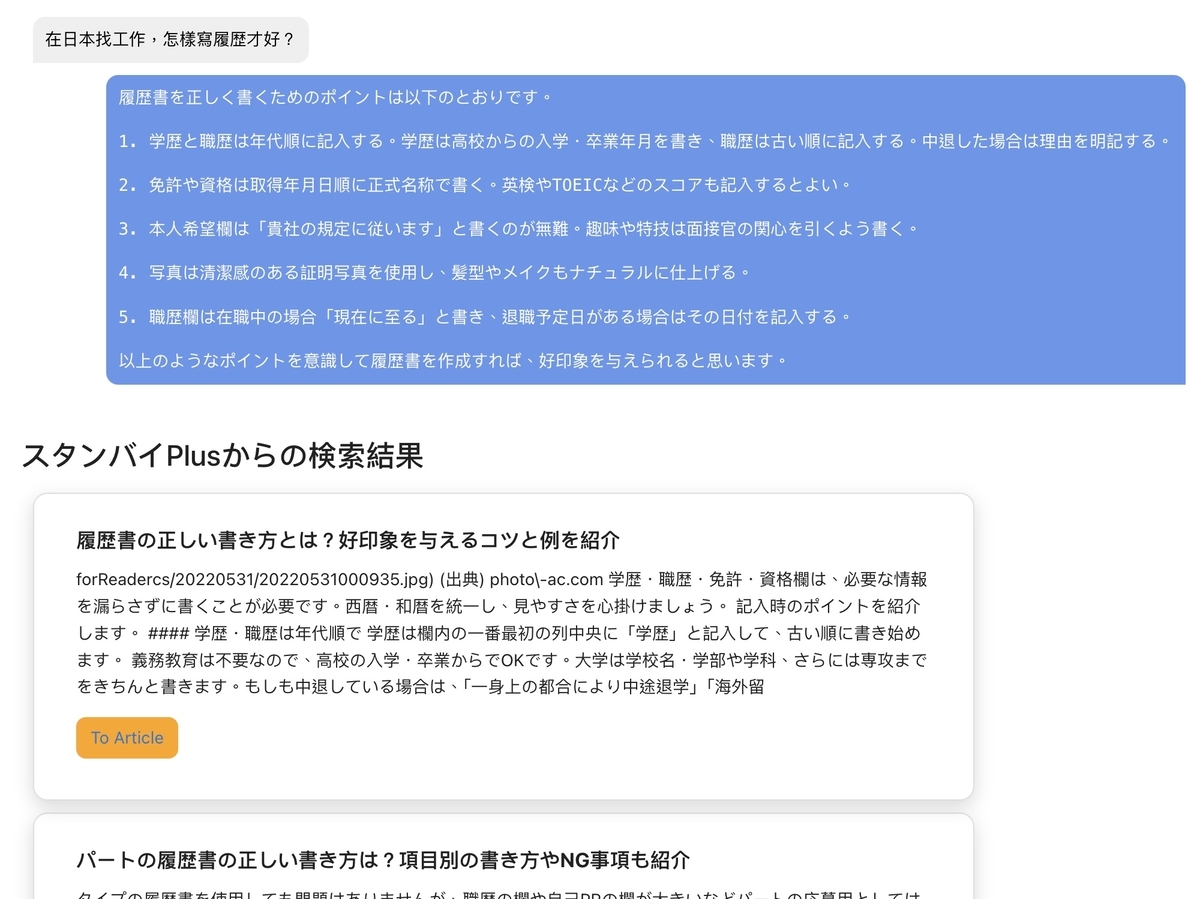 他の言語で質問された際に、質問に利用された言語でそのまま返答します 👍
他の言語で質問された際に、質問に利用された言語でそのまま返答します 👍
結論
Vespaが提供する高度な機能により、このRAGプロトタイプは1日以内で作成できました (フロントエンド言語に慣れていないため、UIの作成に多くの時間を費やしました)。これは、LLMモデルとVespaの可能性を示しています。
プロトタイプの外部公開までまだ長い道があります。以下のようなアイディアでさらなる改善を検討しています。
- より良いリトリーバルのために、e5 モデルを当社のデータでファインチューニングする
- より良いColBERTモデルを学習する (現在もColBERTをまだ実験中)
- プロンプトの悪用防止対策 (このプロトタイプは内部使用のため、これについては何もしていません)
- 生成されたコンテンツに、その基になっているものを記載します
スタンバイでは、常に新しいアイデアや技術を調査し、試しています。新しいことに挑戦したい方や、素晴らしいプラットフォームで素晴らしい仲間と仕事をしたい方は、ぜひ採用ページをご覧ください!
スタンバイのプロダクトや組織について詳しく知りたい方は、気軽にご相談ください。 www.wantedly.com