
こんにちは、Searchグループで検索エンジンの開発、運用を担当する小野です。
今回は、検索エンジンVespaのParent/Child機能を活用して広告配信を改善した取り組みについて紹介します。
スタンバイの検索連動型広告
スタンバイの検索結果画面には以下の2種類の枠があります。
- 無料掲載枠: 検索条件との一致度に基づいて求人票を掲載
- 広告枠: 検索条件との一致度+キャンペーンの入札金額に基づいて求人票を掲載
広告主はキャンペーンを設定することで、広告枠に自社の求人票を表示できます。
キャンペーンには、ターゲットとなる検索条件や入札金額、予算、配信期間などを指定できます。
無料枠と同様に検索エンジンにはVespaを採用しており、求人票とキャンペーン情報をインデックス化し検索処理を行っています。
関連記事
- スタンバイの広告表示におけるロジックについて
- 検索エンジンをVespaへ移行しています
キャンペーン更新時の課題
広告配信用のVespaにはデータ構造の影響でFeed処理に時間がかかるという課題がありました。
当初は求人票の単一のスキーマで構成されており、キャンペーン情報は求人票に埋め込まれていました。
# 求人票のスキーマ例
{
"document_id": "id:default:campaign:1234",
"job_title": "hoge",
{
"campaign_id": "1234",
"start" : "2025/01/01",
...
}
...
}
一方、Feed処理は以下のケースで行われます。
- 求人票の更新
- キャンペーンの設定情報の更新
- キャンペーンの予算切れによる更新
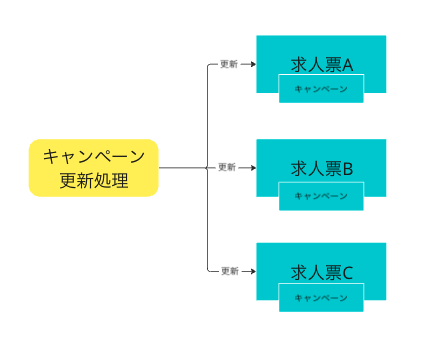
冗長なデータ構造によりキャンペーン情報を更新するたびに、関連するすべての求人票を更新する必要がありました。
例えば、1キャンペーンに1万件の求人票が紐づいている場合、100件のキャンペーンを更新すると100万件の求人票を更新することになります。
10万件の求人票を更新するのに3分かかるとすると、全体の更新は30分かかってしまいます。
VespaのParent/Childを活用
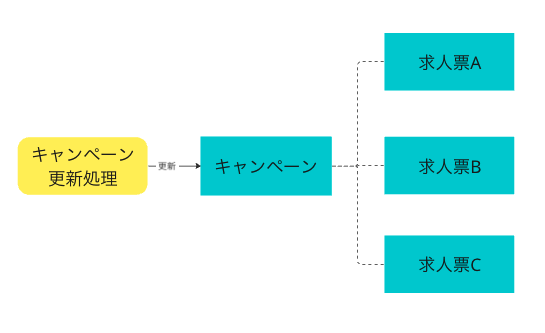
VespaのParent/Child機能を利用すると、親子関係のドキュメントを階層化できます。
子ドキュメントに親ドキュメントのIDを指定することで、検索時に親の情報を参照できます。
また、親ドキュメントは全コンテンツノードに複製されるため、検索パフォーマンスを維持しつつ、効率的なFeed処理が可能になります。
スタンバイでは、キャンペーンを親ドキュメントとして定義し、求人票のスキーマには親キャンペーンのドキュメントIDを参照する形に変更しました。
# Parent-Childを使ったデータ構造例
## キャンペーン(親)
{
"document_id": "id:default:campaign:1234",
"campaign_id": "1234"
"start" : "2025/01/01"
...
}
## 求人票(子)
{
"document_id": "id:default:job:abcd",
"campaign_ref": "id:default:campaign:1234",
import campaign_ref.start as campaign_start
...
}
この変更により、
- キャンペーンの更新時はキャンペーンのみ更新
- 求人票の更新時は求人票のみ更新
といった最小限の更新処理が可能になり、キャンペーンの更新にかかるFeed処理時間を大幅に短縮できました。
先程の100件のキャンペーンの更新する例では、処理時間を数秒まで短縮されます。
導入時の検証と課題
検索時のレイテンシ検証
Feed処理の効率化は確認できましたが、検索時のレイテンシに影響がないか検証しました。
直接参照から間接参照になったことで少なからず検索パフォーマンスが悪化する懸念されましたが、負荷試験の結果、レイテンシ悪化はほぼ発生しませんでした。
Vespa公式ブログでは親ドキュメントと子ドキュメントの件数比が小さいほど、パフォーマンスへの影響が大きいと言及されています。
今回は、キャンペーンと求人票の件数比がとても大きく(約1:10,000)、importする項目も少なかったため影響は軽微でした。
圧倒的なFeedの効率化に対して、検索パフォーマンスの悪化がないことは大きなメリットでした。
複数スキーマ移行による課題
キャンペーン用のスキーマを追加したことで以下の問題が発生しました。
- 検索ヒット件数の変動
- スキーマごとのリソース指定エラー
- リソース使用率の増加
Vespaでは、デフォルトで全スキーマに対して検索が行われるため、複数スキーマになると意図しない挙動が起こり得ます。
例えば、求人票(job)の検索でRankProfileを指定しているとキャンペーン(campaign)のスキーマを追加したことで以下のエラーが発生します。
# エラー例 $ vespa query "select job_title from job where true" ranking=PiyoRankProfile → エラー発生 Source 'job': 4: Invalid query parameter: schema 'campaign' does not contain requested rank profile 'PiyoRankProfile'
検索対象のスキーマを限定するには、restrictパラメータを利用します。
# 修正版 $ vespa query "select job_title from job where true" ranking=PiyoRankProfile restrict=job → OK
特にエラーがない場合でも、restrict指定がないと無駄なリソースを使用してしまうため適切な指定が必要です。
まとめ
VespaのParent/Child機能を導入することで、キャンペーン更新時のFeed処理時間を大幅に短縮できました。
また、データ構造がシンプルになったことで開発効率も向上しました。
今後もVespaの機能を活用し、さらなる改善を進めていきたいです。
検索エンジンの開発に興味を持たれた方は、採用サイトよりお気軽にお問い合わせください。
スタンバイのプロダクトや組織について詳しく知りたい方は、気軽にご相談ください。 www.wantedly.com