
はじめに
求人検索エンジンのスタンバイでは全国の仕事情報から自分のニーズにあった最適な求人を探すことができます。 この記事では、スタンバイの検索の仕組みを紹介します。
検索エンジンの概要
一般的に検索エンジンは複数のフェーズから成り立つシステムです。 以下の図は検索エンジンを構成するフェーズを表しています。
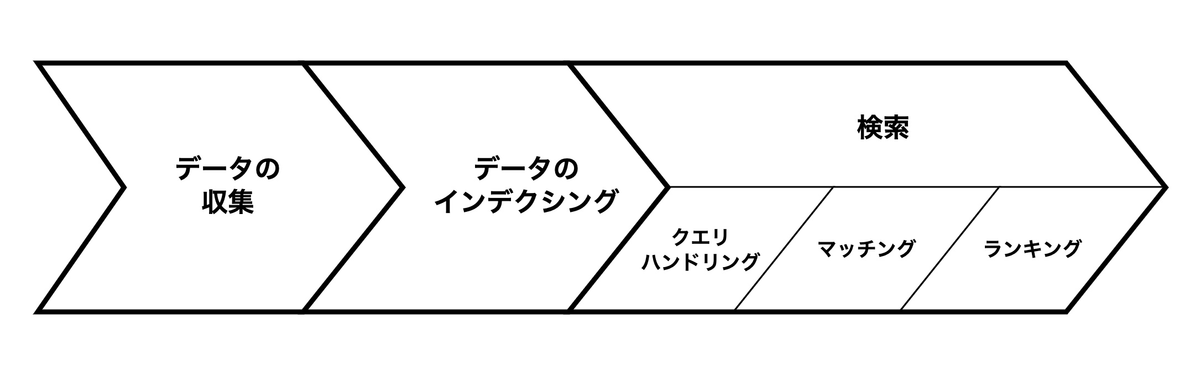
検索エンジンには、大きく分けてデータの収集、データのインデクシング、検索の3つのフェーズがあります。 データの収集フェーズでは検索対象とするデータをさまざまなソースから集めてきます。スタンバイの場合、取り扱うデータは求人票です。 データのインデクシングフェースでは、取得してきたデータで検索エンジンのインデックスを構築します。 インデックスとは索引という意味で、検索のために事前準備しておくデータです。 検索エンジンはインデックスを活用することで高速に検索結果を返すことができます。 検索フェーズでは、検索エンジンがユーザからリクエストを受け取った際に実際に検索を実施するフェーズです。 検索フェーズはさらにクエリハンドリング、マッチング、ランキングという3つのステップに分かれます。 クエリハンドリングではユーザが検索エンジンに入力したクエリの分析をおこない、検索に適した形へクエリを変換します。 マッチングでは検索エンジンの全てのデータの中からクエリに合うデータを絞りこみ検索結果として取得します。 最後のランキングでは、取得したデータをユーザのニーズにあった順番へ並び替えます。
以降では、検索エンジンのそれぞれフェーズについて、スタンバイではどのような仕組みになっているかを紹介します。
スタンバイの検索エンジンの仕組み
データの収集
スタンバイで扱う求人票はさまざまなところから取得しています。取得元の種類としては、 クローリング、XMLフィード、スタンバイで求人票を作成する、などがあります。
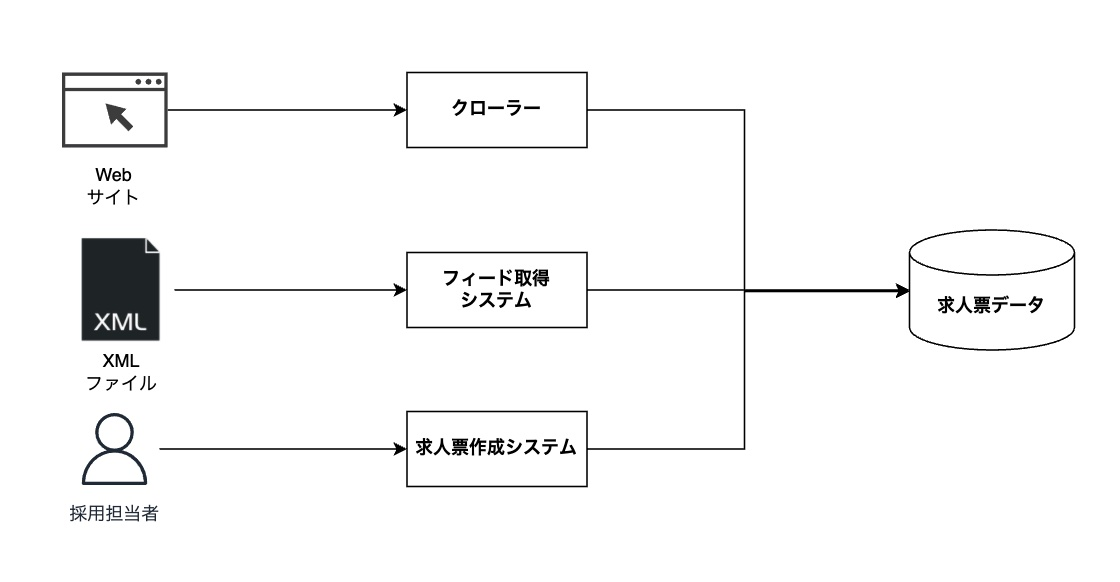
クローリングでは、クローラーというプログラムが求人票を掲載しているサイトのHTMLを取得・解析し、データを抽出して求人票を集めてきます。 サイトごとにページの作りが異なるので、クローラーはページのどの部分を見て情報を抽出するかを正しく判定し、データを抽出する必要があります。 XMLフィードでは、求人票掲載元の企業のサーバーにあるデータを取得したり、スタンバイのサーバーに求人票データを置いてもらったりすることで求人票データを取得します。この方法で取得するデータはXMLファイル形式で扱います。 また、スタンバイが提供している求人票を作成する機能を使うことも可能です。 この場合は直接求人票データをスタンバイ内のデータベースに保存するため、そこからデータを取得します。
データのインデクシング
上記のようにして集めてきたデータを検索システムのインデックスに登録するのですが、 データの形式や求人票の書き方がそれぞれで異なるため、データをインデクシングする前に内部で扱いやすい形式に変換しています。 これにより、例えば、給与を数値型に変換することで時給○円以上の求人票だけ絞り込むといったことをできるようにします。
また、求人票ごとに検索で使用するための追加の情報の付与も行います。 具体的には、求人票が一定期間に何回クリックされたかといった実績データや、求人票のデータから推測した求人のカテゴリなどです。 これは、マッチングの精度の改善やランキングの改善のために、後述する機械学習ランキングモデルの特徴量データとして使用されます。
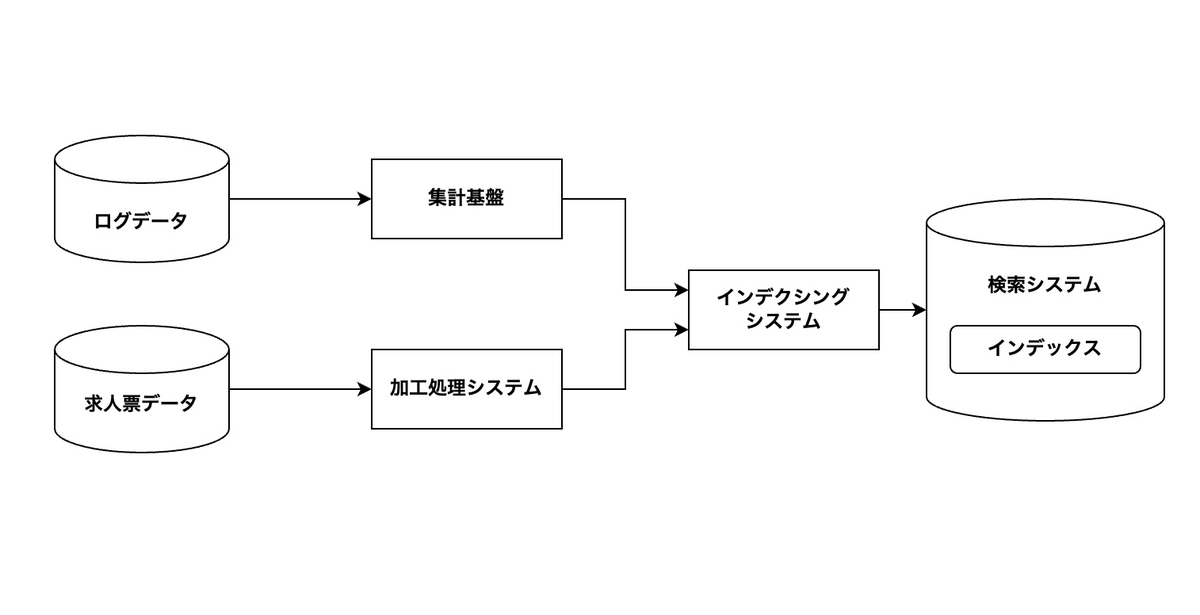
このようにして、求人票データのインデクシングを行っているのですが、 求人票データの特徴として更新頻度が高いということにも注意しなければなりません。 求人票は、企業が求職者を採用できた時点で無効になってしまいます。 このため、終了した求人を削除し検索結果へ表示されないようにしないといけません。 また、求人票の情報が更新された場合、インデックスにも素早く反映させる必要があります。 このように、大量の求人票データを素早く処理する必要があるため、 インデクシングの実装ではストリーミング処理を行うなど様々な工夫をしています。
検索
ここまでは、検索を実施する前のデータを準備するフェーズを説明しました。 ここからは、実際にユーザが求人票を検索を実施する際に行われる処理を説明していきます。
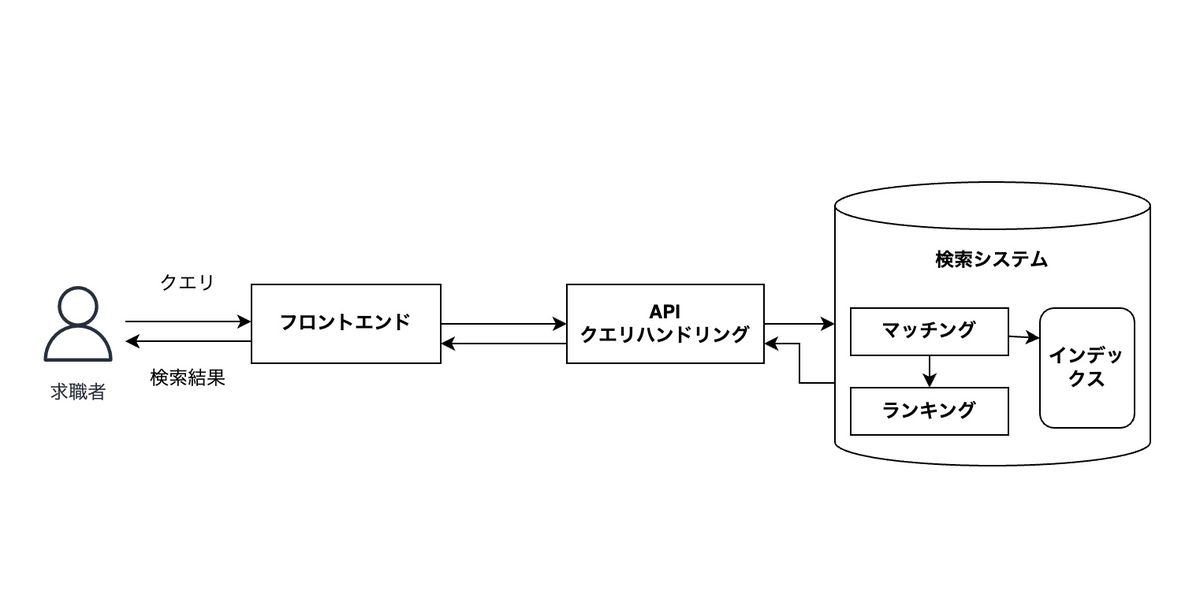
クエリハンドリング
ユーザが入力したクエリはまず最初にバックエンドのAPIに渡されます。 ここで、受け取ったクエリを検索システムで使用する形式に変換します。 また、単に変換するだけではなく、検索品質を改善するためにさまざまな処理を実施しています。 例えば、クエリに会社名が含まれている場合、その部分だけ抽出してインデックスの会社名のフィールドへマッチさせるようにします。また、雇用形態に関する文字列が含まれている場合、内部的なコード表現に変換することで、文字列が完全に一致していない場合でも同じ意味の雇用形態の求人票を取得できるようにしています。このように、ユーザが入力したクエリを分析し・適切な処理を施すことは検索結果の品質を向上させるために非常に重要です。
マッチング
ここからは、検索システムの内部で実施される処理になります。 APIで処理されたクエリが検索システムに入力されると、 検索システム内部では、検索結果の候補となる求人票を取得します。 ここでは、できるだけ高速にユーザが求めているものにマッチするものだけを過不足なく取得することが求められます。
スタンバイでは検索システムにYahoo! Japanが開発しているABYSSを使用しています。 ABYSSはYahoo! Japanのさまざまなサービスで利用されており、ABYSSを利用することで、これまでYahoo! Japanの中で培われてきたさまざまな検索技術のノウハウを検索品質の改善に取り入れることができています。また、後述する検索用の独自プラグインを利用することで機械学習を用いたランキングの改善ができるようになっています。
ランキング
マッチングの後に取得した結果を並べ替えます。 検索エンジンはユーザが入力したクエリに対して、マッチした結果をユーザのニーズにあった順番で返すことが必要です。なぜなら、検索にヒットした結果がたくさんあってもユーザは全てを見ることができないからです。そのため、検索結果のランキングの改善も非常に重要になります。
ランキングの改善方法として、機械学習を使って検索結果を並び替えるランクキング学習という手法がよく知られています。ランクキング学習では、機械学習モデルを検索結果の並び順が最適になるように学習させます。検索時にはこの学習済みモデルを使用して、検索結果を並べ替えます。
スタンバイではYahoo! Japanで独自開発しているSolrのプラグインを利用して、機械学習モデルによるランキングを実現しています。ランキングモデルの特徴量としては、求人票自体の特徴に加えて、インデクシングフェーズの説明で述べたように、ログから集計した求人票ごとのクリック数などの実績データも使用しています。
まとめ
この記事では、スタンバイの検索の仕組みを紹介しました。 検索エンジンは複数のフェーズから構成されるシステムであり、 それぞれのフェーズで、さまざまな技術的課題が存在します。 スタンバイはそれらの課題に対して専門のチームが複数存在しており、 日々解決に取り組んでいます。各チームがどのようなことをやっているかは、 それぞれのチームの記事をご確認ください!
スタンバイのプロダクトや組織について詳しく知りたい方は、気軽にご相談ください。