
はじめに
こんにちは、スタンバイでプロダクト企画をしている荒巻です。
スタンバイでは、日々サービスを改善するために様々な技術的挑戦をしています。今回はその中でも、求人データ保管・配信システムの刷新プロジェクトに伴って発生した大きな課題に対し、課題分析から要件定義、そして生成AIの力を借りて「自分で作ってみよう!」と思い立ち、社内ツール開発に至った経緯とそのプロセスをご紹介します。
開発したのは「SQL Converter」という、既存のSQLクエリを新しいデータ構造に合わせて自動変換するツールです。最大で約1200件ものクエリ書き換え作業を効率化するために、AI Co-Pilot(GitHub Copilot / Google Gemini)とAWS Bedrock (Claude) を活用しました。
この記事は、以下のような方に特におすすめです。
- AI/LLMを活用した開発や業務効率化に関心のあるエンジニア・非エンジニアの方
- SQLやデータ移行、データ基盤の刷新に関心のある方
- 課題発見から解決策の具体化、ツール開発までのプロセスに興味がある方
- 大規模なシステム改修における課題解決の事例を知りたい方
この記事を通して、身近な課題を分析し、生成AIなどの新しい技術を活用することで、専門家でなくても解決策を形にできる可能性を感じていただければ幸いです。
プロジェクトの背景と課題分析
スタンバイでは、求人データを保管・配信する既存システム(通称: job-store)のパフォーマンスとコストに課題があり、システム構成を刷新するプロジェクトが進行しています。その過程で、新しいデータ構造を持つシステム(通称: jphub)を導入するため、データ基盤へ反映されるデータ構造も新しくなります。
これは大きな前進でしたが、同時に新たな課題が発生しました。スタンバイでは、営業、企画、エンジニアなど、様々な職種のメンバーがデータ分析やモニタリングのために、Redash等でSQLクエリを利用していました。データ構造が変わるということは、これらの既存クエリ(その数、約1200件!)を新しい構造に合わせて書き換える必要がある、ということです。
実際に調査・分析を進めると、この書き換え作業にはいくつかの大きな困難(ペインポイント)がありました。
- マッピングの複雑性: 旧データ構造(RDBライク)から新データ構造(NoSQLライク)への変更であり、単純なテーブル名・カラム名の置換だけでは対応できません。データ構造自体の変更を理解し、適切にSQLを書き換える必要がありました。これは、特にSQLに習熟していないメンバーにとっては高いハードル。
- 膨大な作業量: 対象クエリが約1200件と非常に多く、すべてを手作業で書き換えるには膨大な工数が必要。
- 限られた時間: プロジェクトのスケジュール上、書き換え作業に割ける期間は半年もなく、人的リソースの確保も難しい状況。
このまま手作業で進めるのは非現実的であり、何らかの効率化策が急務でした。
効率化への道筋:要件定義
課題分析の結果、「人手で行う作業コストを低減する仕組み」の導入が不可欠であるという結論に至りました。ただし、完全に自動化するのではなく、最終的な結果の確認は必ず人手で行う方針としました。
そこで、SQL書き換え作業を支援するツールの開発を検討し始めました。そのツールが満たすべき主要な要件を以下のように定義しました。
- マッピング情報の利用: 新旧データ構造のマッピング情報を読み込み、それに基づいて変換できること。
- SQL変換機能: ユーザーが入力した旧SQLを、マッピング情報に沿って新SQLに変換し、結果を提示できること。
- エラー対応: 変換後のSQLを実行してエラーが出た場合に、そのエラー情報を考慮して再度変換を試みられること。
- Redash連携: Redashから既存クエリの情報を取得できること。
- シンプルさ: 様々な職種のメンバーが利用するため、直感的に使えるシンプルなインターフェースであること。
- (非機能要件) セキュリティ(VPN接続必須)、コスト効率(低利用時は停止)なども考慮。
「これ、AIで作れるかも?」 - 開発への決意
これらの要件を定義していく中で、特に「マッピング情報に基づいてSQLを変換する」というコア機能は、近年の生成AI技術、特に大規模言語モデル(LLM)が得意とする領域ではないか?と考え始めました。
複雑なルール(マッピング情報)と入力(旧SQL)を理解し、それに基づいて新しい出力(新SQL)を生成するタスクは、まさにLLMの能力が活かせる場面です。さらに、GitHub CopilotのようなAI Co-Pilotを使えば、Webアプリケーションの骨組みや定型的なコードも効率的に生成できるため、「プログラミング経験がなくても、AIの力を借りれば自分でこのツールを作れるのではないか?」という思いが強くなりました。
こうして、「AIを活用したSQL変換ツール」の具体的な開発がスタートしました。
解決策:AIによるSQL変換ツール「SQL Converter」
この課題と要件、そして「AIで作れるかも」という発想から生まれたのが、社内ツール「SQL Converter」です。旧データ構造に基づいたSQLを入力すると、新データ構造に対応したSQL候補を自動で生成してくれるWebアプリケーションとして実現しました。
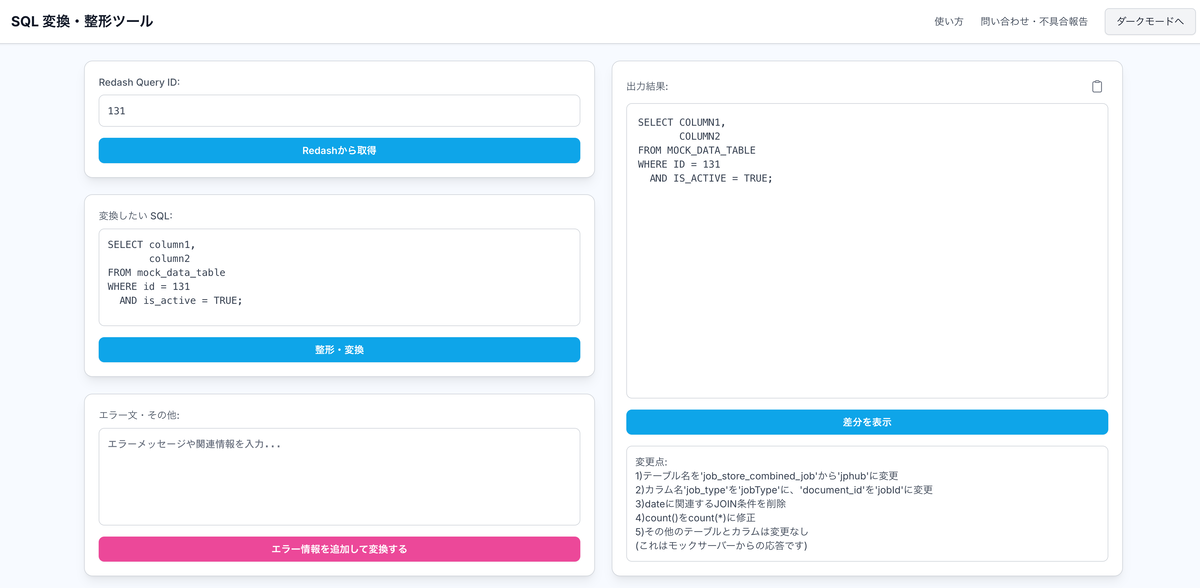

▲SQL Converterのメイン画面
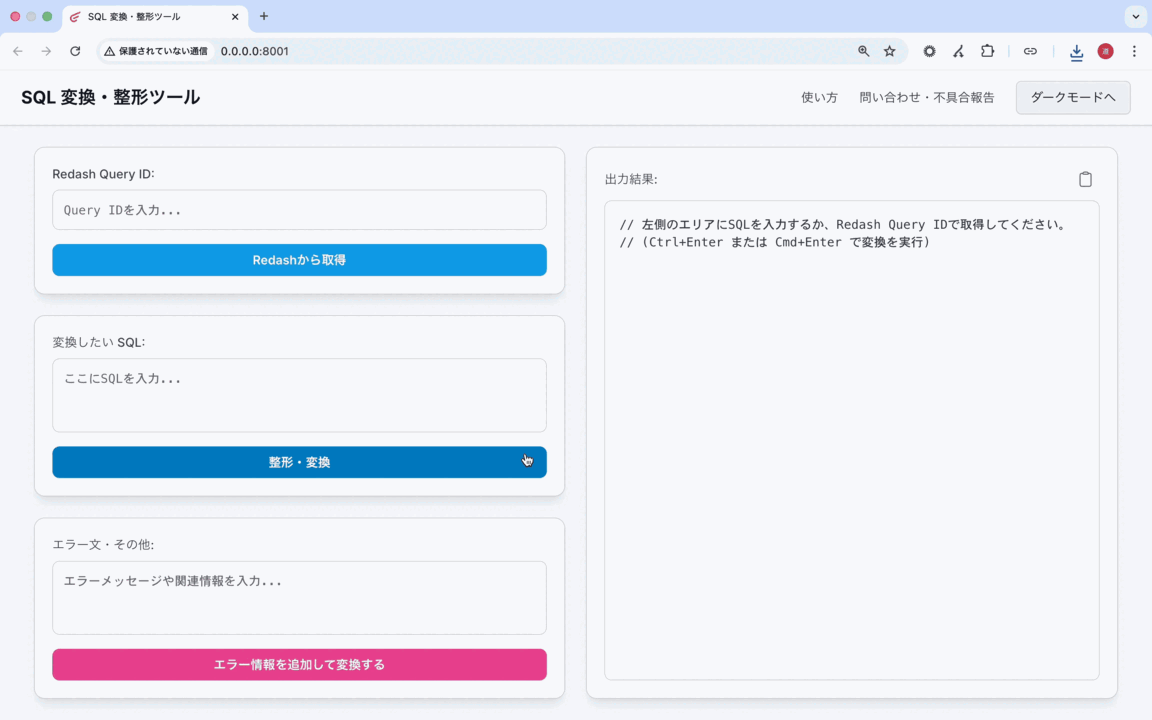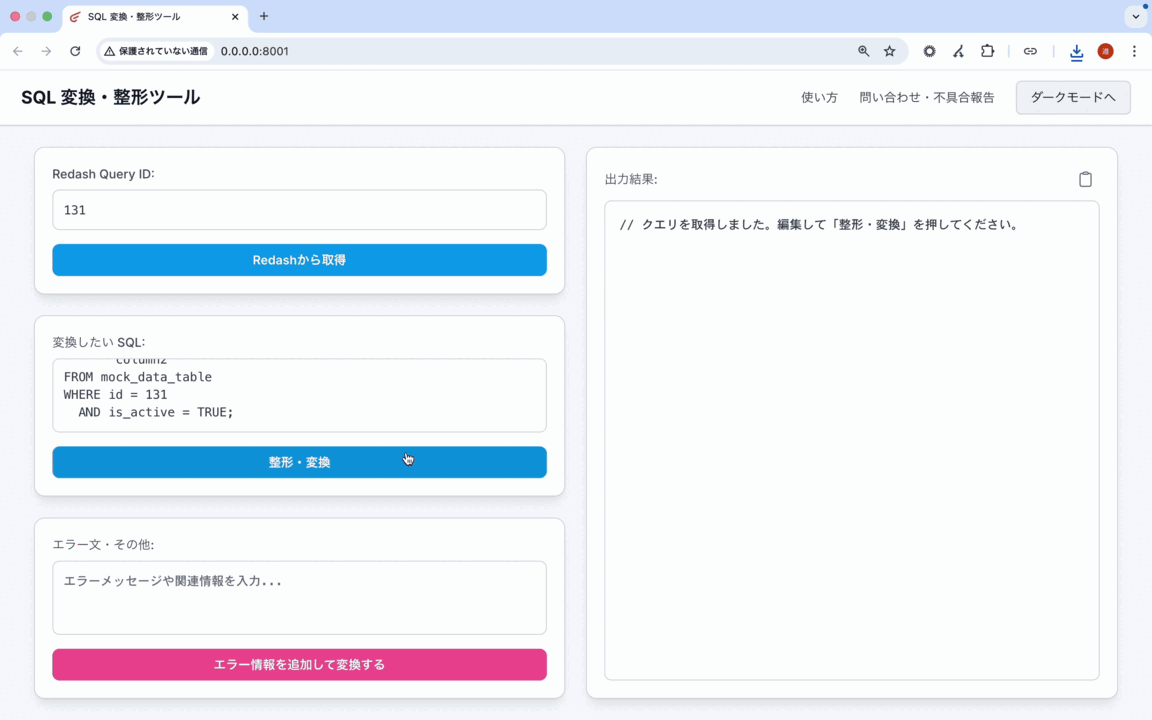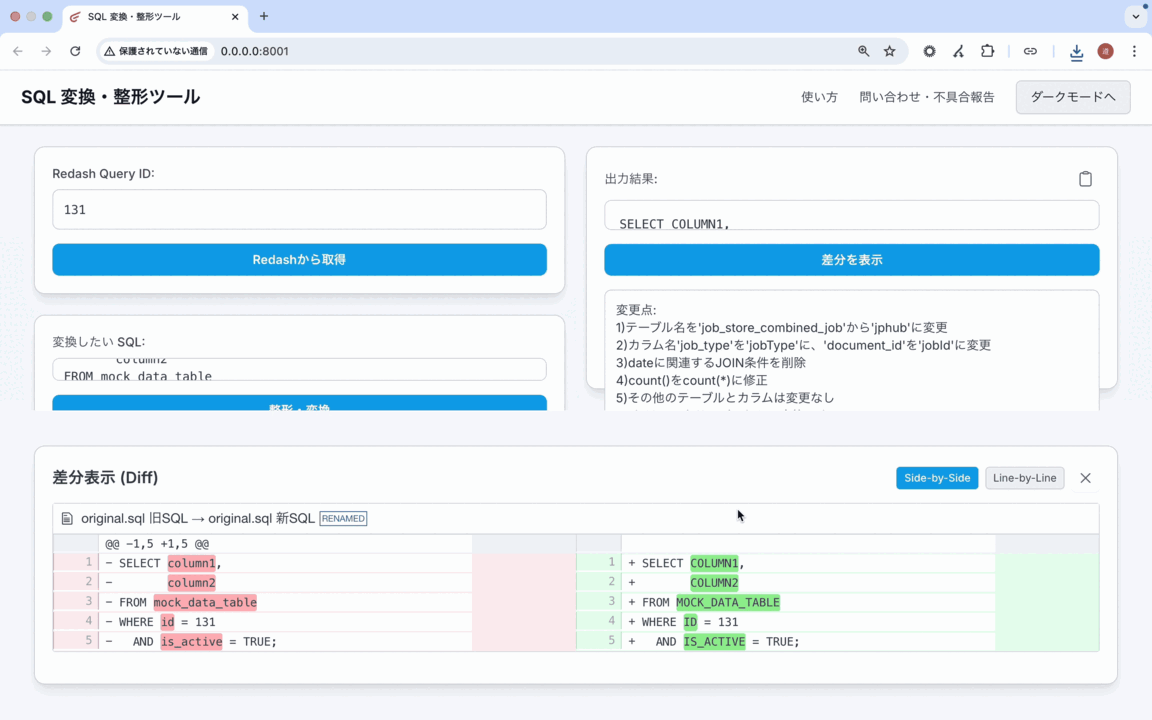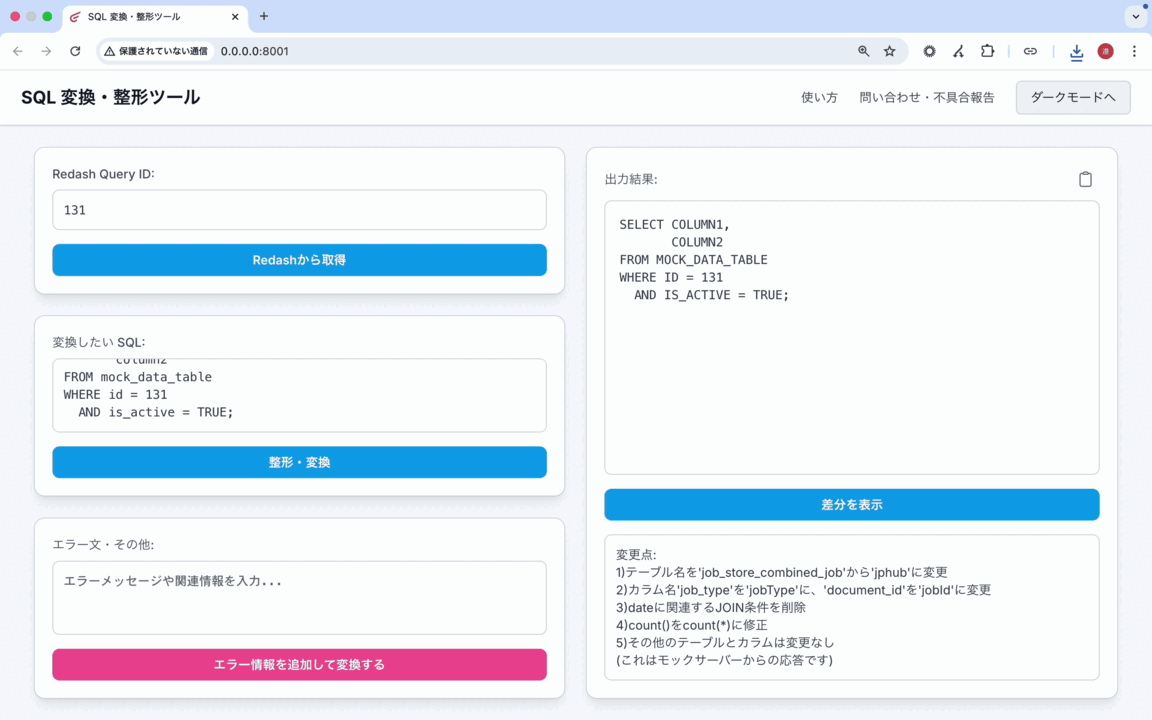 ▲実際にSQLを変換している様子(ダミーデータによる動作例)
▲実際にSQLを変換している様子(ダミーデータによる動作例)
主な機能は以下の通りです。
- SQL入力: 変換したいSQLを直接入力、またはRedashに保存されているクエリのIDを指定して読み込むことができる
- AIによる変換: 入力されたSQLと、事前に定義された新旧マッピング情報をもとに、AI(AWS Bedrock - Claude)が新しいSQLを生成。変換時にエラーが発生した場合は、そのエラー情報を追加して再度変換を試みることも可能
- 差分表示: 変換前後のSQLの差分(Diff)を並べて表示し、変更点を視覚的に確認できる
ツールの技術構成
ツールの技術スタックは比較的シンプルに構成しました。
- バックエンド: FastAPI (Python)。社内での導入事例もあり学習コストが低いと考え選定しました。
- フロントエンド: HTML, CSS (Tailwind CSS), JavaScript。Tailwind CSSはメジャーなフレームワークであるため採用しました。
- AIモデル: AWS Bedrock (Claude)。社内での利用実績があったため採用しました。
- 設定・変換ロジック:
mapping_info.yml: 新旧のテーブル・カラム対応関係を定義したマッピングファイル。prompt.txt: Bedrockに渡す指示(プロンプト)のテンプレート。
特別なフレームワークやライブラリへの依存を極力減らし、基本的なWeb技術とAIサービスを組み合わせることで、迅速な開発とメンテナンス性の確保を目指しました。
AI Co-Pilot と共に歩んだ開発プロセス
今回のツール開発では、GitHub CopilotやGoogle GeminiといったAI Co-Pilotを全面的に活用しました。これにより、プログラミング経験がほとんどない自分でも効率的に開発を進めることができました。
開発の進め方:「輪郭から詳細へ」
開発は、まるで絵を描くように、まず大まかな輪郭(UI)から描き始め、徐々に詳細(機能)を加えていくアプローチを取りました。
- フロントエンド作成: まずHTMLとCSS(Tailwind)で基本的な画面構成を作成。
- モックAPI作成: フロントエンドからのリクエストを受け付け、ダミーデータを返す簡単なFastAPIサーバーを作成。
- フロントエンド動作確認: モックAPIを使って、ボタンクリックや表示切り替えなど、フロントエンド(JavaScript)の動作を実装・確認。
- バックエンド機能実装: 実際のバックエンドに、Redash連携、Bedrock連携などの機能を1つずつ追加。ここでもモックAPIを参照しながら、期待通りの動作をするか確認しつつ進めました。
- 本番API連携: 最後に、バックエンドと実際のAWS Bedrock、Redash APIを連携させ、全体の動作を確認。
この段階的なアプローチにより、手戻りを最小限に抑えつつ、着実に開発を進めることができました。
モックサーバーの重要性
特に重要だったのが、ステップ2で作成したモックサーバーの存在です。AI Co-Pilotは非常に強力ですが、常に完璧なコードを生成してくれるわけではありません。実際にAIが生成したコードには、越えなければならない「3つのチェックのハードル」があると感じています。
- 見た感じ良さそうか?: ブラウザ画面で見て意図通りの変更になっているか。
- ちゃんと動きそうか?: 実際に動かしてみて、エラーなく実行できるか。
- 意図通り正しく動いているか?: 実行できても、期待した通りの結果や内部状態になっているか。
AIは最初のハードルは超えてくることが多いですが、2番目、特に3番目のハードルを一発で超えることは稀です。そのため、何度も「生成→試行→修正」というループを回す必要がありました。
ここでモックサーバーが真価を発揮します。AIが生成したコードを「さっと見られる環境」「すぐに試せる環境」を提供してくれます。
- 迅速な動作確認: フロントエンドやバックエンドのロジックが期待通りに動きそうか(ハードル2)を、実際のAPI連携や外部サービスの接続状態を気にせず、手元ですぐに確認できる。これにより、フィードバックループが非常に高速になる。
- 関心事の分離: 例えばフロントエンドのテスト中はUIの挙動だけに集中でき、バックエンドAPI側の問題を切り分けて考えることができる。これにより、問題の特定と修正が容易になる。
AI Co-Pilotとのペアプログラミングにおいて、この「すぐに試して、すぐにフィードバックを得られる環境」は、開発効率と試行錯誤の質を大幅に向上させる鍵となりました。
プロンプトエンジニアリングの試行錯誤
AIにSQL変換を正確に行わせるためには、Bedrockに渡す指示、つまりプロンプトの質が非常に重要です。ここでも試行錯誤を繰り返しました。
最初は、「このSQLをマッピング情報に基づいて変換して」といった非常にシンプルな指示から始めました。しかし、これだけでは以下のような問題が発生しました。
- 元のSQLに含まれる改行やインデント、コメントは無視されてしまう。
- 変換の精度は十分でない場合がある。
- ツールが出力する説明メッセージのフォーマットは扱いにくい。
そこで、実際にツールを動かして問題点を洗い出し、AI Co-Pilotにも相談しながらプロンプトを改善していきました。「フォーマットやコメントはそのまま保持してほしい」「説明文の改行はHTMLの<br>タグにしてほしい」「結果はJSON形式で、'sql'と'message'というキーで返してほしい」といった具体的な指示を追加していったのです。
試行錯誤の結果、最終的に以下のようなプロンプト (prompt.txt) に落ち着きました。
以下のSQLを、提供されるマッピング情報に基づいて新しいデータベース(テーブル)に対応するように変換してください。
**重要な指示:**
* 入力SQL内の **改行、インデント、空白** を可能な限り **忠実に保持・再現** してください。自動的なコード整形は行わないでください。
* 入力SQLに含まれるコメント (`--` から始まる行や行末コメント) も **そのままの位置で保持** してください。
* マッピング情報に従って、テーブル名やカラム名を適切に置換してください。
* message属性の値である説明文中の改行には、改行文字(\n)ではなく、必ずHTMLの<br>タグを使用してください。
**入力SQL:**
```sql
{input_sql}
```
マッピング情報はこちらです。
```yaml
{mapping_info}
```
結果のアウトプットは以下のjson形式に沿って出力してください。回答はjsonのみ出力してください。
{{
"sql": "ここに変換したSQLを出力",
"message": "ここに変換についての説明を出力"
}}
このように、具体的な指示を細かく与えることで、AIの出力精度と使い勝手を大きく向上させることができました。
AIアシスタントの実践的な使い方
開発全体を通して、AI Co-Pilotは様々な場面で役立ちました。
- 定型コードの生成: FastAPIのエンドポイントの雛形、CSVからYAMLへの変換スクリプトなど、定型的な処理はAIへ任せることで時間を節約できた。
- コードの理解促進: AIが生成したコードへ付与されるコメントが、処理内容の理解を助けた。
- エラー解決のヒント: 行き詰まった際、エラーメッセージを入力すると、解決策の候補を示した。
- ドキュメント作成の効率化: 実は、このツールのREADMEへ記載したシステム構成図やシーケンス図(Mermaid記法)は、ソースコードを元としてAI Co-Pilotが生成したものである。コーディングだけでなく、ドキュメント作成作業も効率化できた点は大きな発見であった。
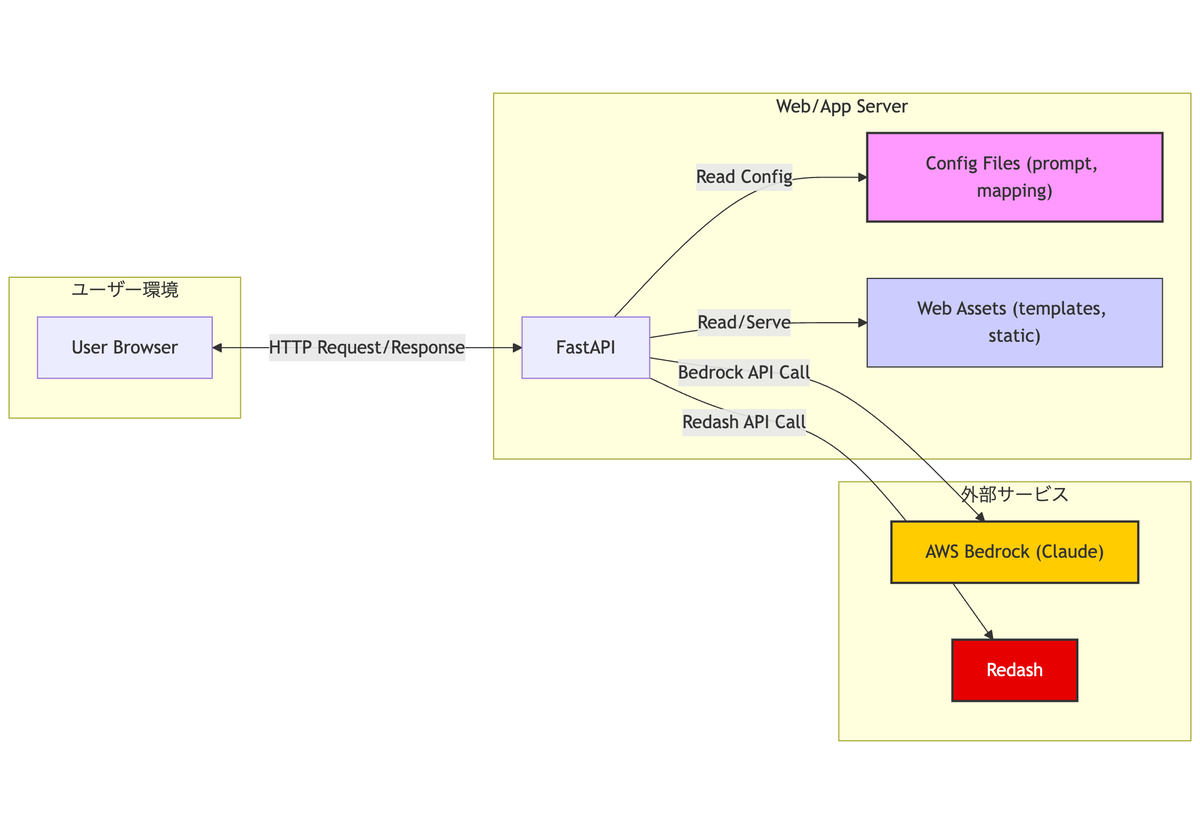 ▲AI Co-Pilotが生成したシステム構成図 (Mermaid)
▲AI Co-Pilotが生成したシステム構成図 (Mermaid)
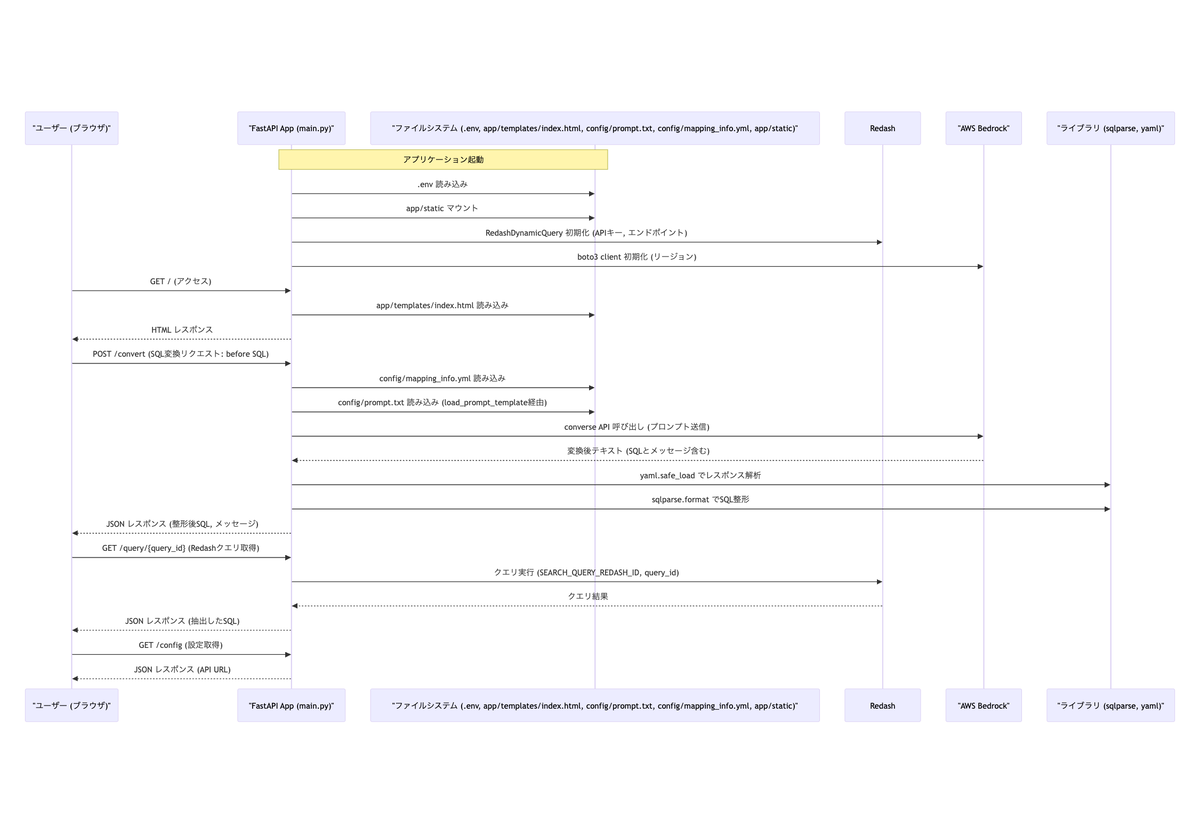 ▲AI Co-Pilotが生成したシーケンス図 (Mermaid)
▲AI Co-Pilotが生成したシーケンス図 (Mermaid)
AI Co-Pilotを使う上で学んだこともあります。それは一度に多くのことを依頼しないことです。例えば「この機能全体を作って」のような大きな依頼は避けるべきです。「このボタンがクリックされたらこのAPIを呼び出す処理を追加して」といった具体的で小さな単位で依頼する方が効果的です。その方が意図に近いコードを得やすく修正も容易になります。一度に多くの要素を生成させると問題が生じがちです。各要素は微妙に正しくても組み合わせると意図しない動作になることがありました。
ツール導入の結果と学び
開発された「SQL Converter」は、jphubへのデータ構造変更に伴うSQL書き換え作業において、大きな助けとなりそうです。完全に自動で完璧なSQLが出力されるわけではありませんが、AIが生成したSQL候補をベースに人間が確認・修正することで、ゼロから書き換える場合に比べて 大幅な工数削減 が期待できます。
主な学び
このプロジェクトを通して、私は多くの学びを得ました。
- AIによる開発の民主化: 生成AIとAI Co-Pilotを活用することで、必ずしもプログラミングの専門家でなくても、アイデアを形にし、実用的なツールを開発できる可能性を実感した。
- 反復的アプローチとモックの重要性: AI支援開発においては、細かく試行錯誤を繰り返すことが重要であり、そのサイクルを高速化するためにモックサーバーのような「すぐに試せる環境」が非常に有効であった。AIが生成するコードの「3つのハードル」を効率的に越えるためにも不可欠である。
- プロンプトエンジニアリングの価値: AIの能力を最大限に引き出すためには、的確な指示(プロンプト)を与える技術が重要になる。試行錯誤を通じてプロンプトを改善していくプロセスは、AI開発の核心の1つと言えるだろう。
- AIとの協働のコツ: AIは万能ではない。得意なこと(定型コード生成、アイデア出し、ドキュメント補助)を任せ、人間は最終的な判断や、AIが苦手な複雑な要求の分解・指示出しを行う、といった役割分担が効果的である。小さな単位で依頼し、結果を確認しながら進めることが成功の鍵である。
まとめ
今回はデータ構造変更に伴うSQL書き換え課題に対し、課題分析から要件定義、そしてAIによる「SQL Converter」開発プロセスとその結果をご紹介しました。
この取り組みは、AIが単なる作業の自動化だけでなく、開発プロセスそのものを変革し、これまで技術的な壁によってアイデアを実現できなかった人々にも開発の門戸を開く可能性を示唆しています。コーディングからドキュメント作成まで、AIは開発の様々なフェーズで強力なパートナーとなり得ます。
もちろん、AIが生成したものをそのまま信じるのではなく、人間が適切にレビューをして、最終的な品質に対して責任を持つことは依然として重要です。しかし、AIと上手に付き合う方法を模索すれば、私たちはより速く、そして創造的な形で課題解決へ対応できるようになるでしょう。
最後に
スタンバイでは、常に新しいアイデアや技術を調査し、試しています。この記事で紹介したようなAI活用や、開発プロセス改善に興味がある方、私たちと一緒にサービスをより良くしていくことに挑戦したい方は、ぜひ採用ページをご覧ください!お待ちしています!
スタンバイのプロダクトや組織について詳しく知りたい方は、気軽にご相談ください。 www.wantedly.com